|
[Main Contribution] Our work does not aim to improve
supervised
classification by using self-supervision for model evaluation.
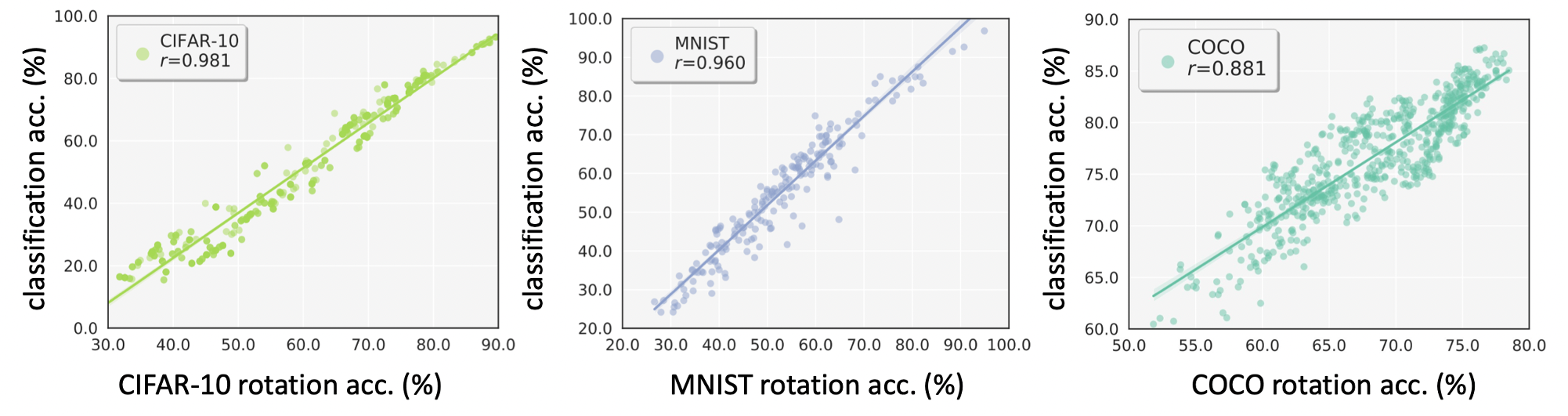
Rather we offer a new and interesting perspective into the relationship between these tasks,
a finding that allows estimation of generalization performance for semantic classification models
from
easily obtained self-supervised rotation prediction results.
Point 1: why use rotation prediction? How about other self-supervised learning
methods?
The self-supervised task should
1) introduce no learning complexity to the main classification,
2) require minimal network structure change, and 3) not degrade classification accuracy.
We choose rotation prediction as the auxiliary task because it meets the above requirements.
In the experiment, we observe using Jigsaw also has a strong correlation,
but it decreases the classification task accuracy (Table 5).
Point 2: Rotation prediction and classification share the features of the last layer
(Layer5).
How about using the previous layer for rotation prediction (e.g., Layer3)?
We have not verified this. However, we believe that as long as
the two
tasks share features,
the correlation can be preserved when the previous layer (e.g., Layer3) is used for rotation
prediction.
Point 3: Can the proposed method be used for model selection and hyper-parameter
search?
For the model selection and hyper-parameter search, they assume
fixed
training and testing sets and that the classifier is changing.
In comparison, we estimate the performance of a fixed classifier on various test environments,
which is
a different problem.
So, this idea appears out of the scope, but it might be interesting to study it in future
work.
Point 4: Can the proposed method be used for other computer vision tasks such as object
detection?
We have not verified this. In order to conduct correlation study,
we need to find more suitable techniques to generate many test sets for object detection,
and we leave it for future work.
|